Building a Scalable ML Workflow with Velda
In the world of machine learning, building a robust and scalable ML workflow is as crucial as the model itself. A well-structured pipeline not only ensures reproducibility but also significantly speeds up experimentation and deployment cycles. Today, we'll explore how to build such a pipeline using Velda's command-line tools that simplify cloud resource management.
Getting Started: vrun, vbatch, and vbatch -f
vrun is your gateway to running commands on the cloud without the headache of managing underlying infrastructure. It's as simple as prefixing your command with vrun, and everything else like packaging is automatically handled. For instance, to run a Python script on an 8-CPU instance, you would use:
vrun -P cpu-8 python my_script.pyFor long-running tasks, you can use vbatch, which runs the command in the background, allowing you to move on to other tasks.
JOB_ID=$(vbatch -P cpu-8 python my_long_running_script.py)The vbatch command prints out a task ID that you can reference later. It also provides a URL for tracking progress. To view the logs of the task in your terminal, use the velda task log command:
velda task log ${JOB_ID}You can also combine these approaches using vbatch -f: Since most errors occur during the initial phase of a job, the -f option waits until the task starts and streams the logs. You can interrupt with Ctrl-C at any time while keeping the task running in the background.
vbatch -f -P cpu-8 python my_long_running_script.py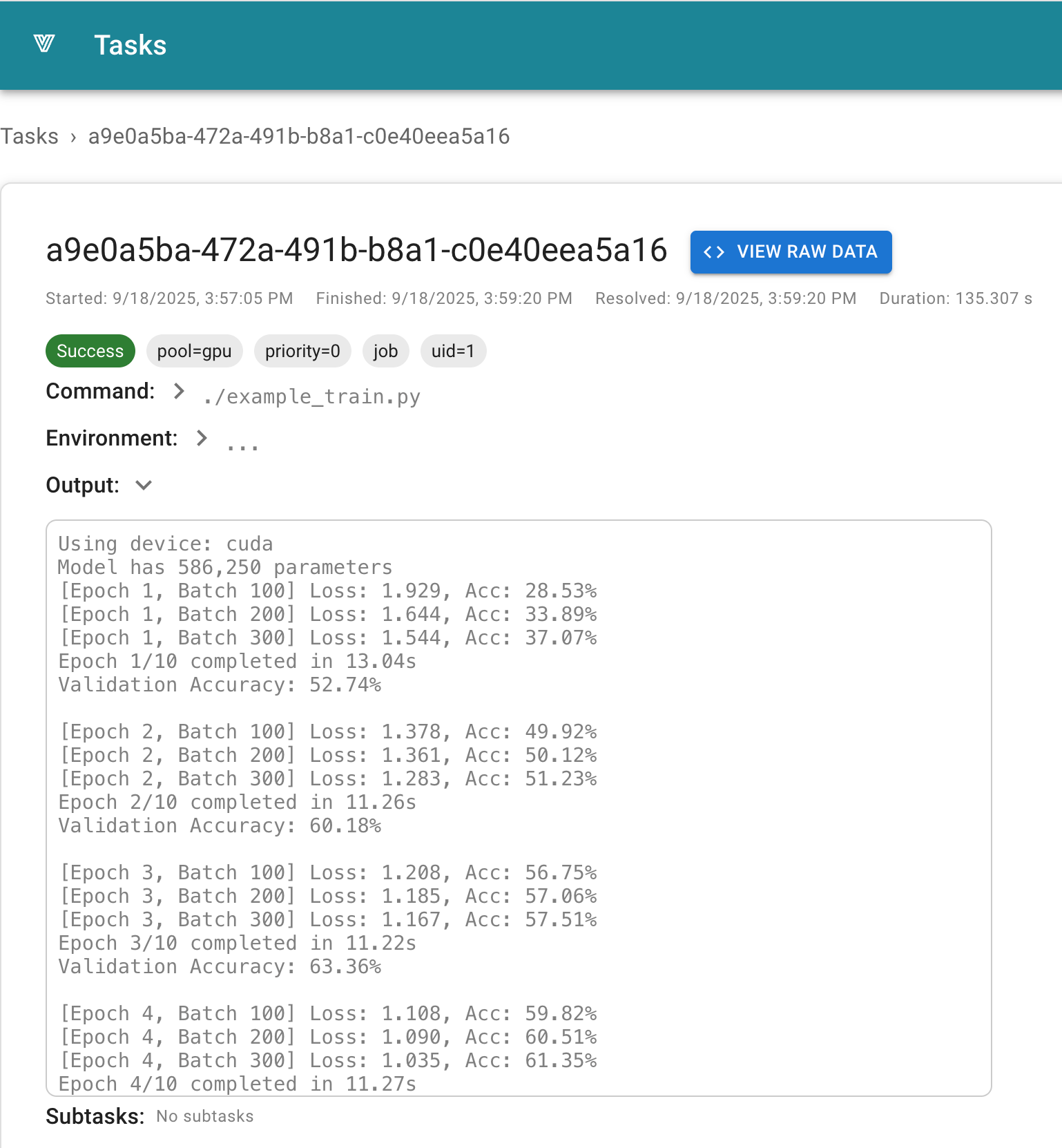
Simple Machine Learning Workflow: Process, Train, Evaluate
Let's build a simple ML workflow with three stages: data processing, model training, and evaluation. We can chain these tasks together using the --after-success flag, which ensures a task starts only after its dependencies have successfully completed. Assuming you already have scripts for each step, creating the pipeline in Velda is as simple as running these commands:
training_pipeline.sh:
#!/bin/bash
# Process the data, e.g. data cleaning
vbatch -P cpu-16 --name process python process_data.py
# Train the model after processing is done
vbatch -P gpu-1 --name train --after-success process python train_model.py
# Model evaluation after training is complete
vbatch -P cpu-8 --name eval --after-success train python evaluate_model.pyThis creates a linear pipeline where each step is executed in sequence. To execute the pipeline, run:
vbatch ./training_pipeline.shAll tasks created within a vbatch script will be automatically grouped as sub-tasks, and the parent task is only marked as complete when all children tasks complete.

Batch Processing: Processing Data in Parallel
In many real-world scenarios, you'll need to process a large number of data files. This is where the "fan-out" pattern comes in handy. We can use standard bash commands like xargs or a for loop to process all files from a source in parallel.
For example, to process all .csv files in a directory:
vbatch bash -c "ls *.csv | xargs -I {} vbatch --name {} -P cpu-8 python process_file.py {}"This command launches a separate task for each .csv file, processing them in parallel. Since it's wrapped under one top-level vbatch command, every individual command is grouped under one parent task for better organization and searchability.
Keep in mind that there's always some overhead for starting a task (about 1 second), so we recommend that each task runs for at least one minute. If needed, you can chunk the inputs:
vbatch bash -c "ls *.csv | xargs -L 100 vbatch -P cpu-8 python process_file.py"This automatically groups up to 100 files in each task and reduces scheduling overhead.
Embedding the Fan-Out in an ML Pipeline
Now, let's embed this fan-out step into a larger ML workflow. We can create a bash script that contains the fan-out logic and then execute that script as a step in our pipeline.
process_all.sh
#!/bin/bash
ls *.csv | xargs -I {} vrun -P cpu-8 python process_file.py {}Now, we can incorporate this into our main pipeline:
# Process all data files in parallel
vbatch -P cpu-16 --name preprocess ./process_all.sh
# Train the model after all files are processed
vbatch -P gpu-1 --name train --after-success preprocess python train_model.py
# Evaluate the model
vbatch -P cpu-8 --name eval --after-success train python evaluate_model.pyThe pipeline above will start train only if all pre-processing tasks has been completed. With that, you can process thousands of data sets without any complex orchestration tools.
Looking for more granular data processing like Ray/DataFlow? No problem, in a future tutorial we will also show how to use Velda to scale up your data processing pipelines.
More Complex Pipelines: Recursive Fan-Outs
For more complex scenarios, you can define recursive pipelines within the fan-out pattern, or any hierarhcy that you need. For example, for each data point, you might want to run inference, evaluate the result, and then aggregate the evaluations. This can be achieved by defining a "sub-pipeline" for each data point.
Let's say we have a script inference_and_eval.sh that takes a data file as input and performs both inference and evaluation:
inference_and_eval.sh
#!/bin/bash
DATA_FILE=$1
# Run inference
vrun -P gpu-1 --name inference ./run_inference.py $DATA_FILE
# Evaluate the inference result
vrun -P cpu-4 --after-success inference ./evaluate_inference.py $DATA_FILENow, we can use this script in our fan-out:
vbatch bash -c "ls *.csv | xargs -I {} vbatch --name {} ./inference_and_eval.sh {}"This creates a two-level pipeline for each data file. The power of this approach is that you can build arbitrarily complex and recursive ML workflows that remain easy to manage and scale.
By leveraging Velda's vrun and vbatch commands along with bash scripting, you can build sophisticated, scalable, and reproducible ML workflows with ease. This allows you to focus on what matters most: building great models.
Getting Started Today
Ready to build your first pipeline? A few options to get started:
- Open Source: Try Velda's open-source edition
- Enterprise: Deploy with SSO, RBAC, and advanced observability
- Hosted(Coming soon): Immediately scale with Velda's managed platform